

Windows Containers: Understanding Images and Layers

It’s been a while since I’ve written about containers on Petri, so I thought it was time to look at one of the most important concepts. While it is easy to grasp the basic idea of how containers work and how they differ from virtual machines (VM), understanding container images and layers is a bit more complicated.
For an overview of using containers in Windows Server 2016, check out First Steps: Docker and Containers in Windows Server 2016 on Petri.
Container Images
Images can be used to create containers but unlike VM images, container images reference a list of read-only ‘layers’ that are stacked to represent changes that were made to the filesystem. For example, each time you execute an instruction in Docker, a new layer is created to represent the changes made to the filesystem.
Docker files can be used to automatically build Docker images. The following Docker file has four instructions, each of which creates a new layer. When you add a new layer, it is writeable, but all the preceding layers become read-only. So, the last layer is always writeable, and it is often referred to as the container layer.
FROM ubuntu:18.04
COPY . /app
RUN make /app
CMD python /app/app.py
In the Docker file above, the last layer specifies the command to run in the container. In this case, a Python app. The container layer is a thin writeable layer that sits on top of the read-only layers in the image. All changes made in the running container are written to the container layer. But when a container is deleted, the container layer is also deleted. The underlying container image is not changed.
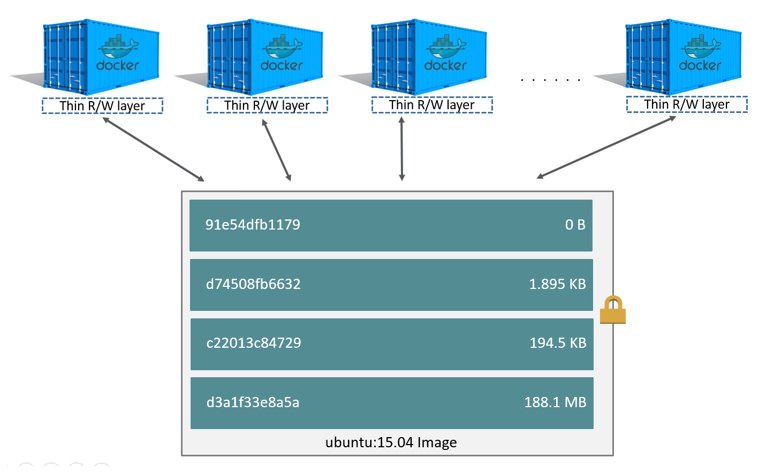
When you create a new container from an image using <docker run>, the container gets its own container layer. This system of stackable layers allows multiple containers to share a single image but maintain their own data state. If your application needs persistent storage, i.e. data should not be deleted with the container or it is a heavy I/O app, Docker data volumes allow data to be written to the host’s disk, instead of to the container layer, by mounting the host server’s filesystem or external storage from inside the container. Containers can also share Docker data volumes.
The Docker storage driver stacks and maintains layers, and lets layers be shared across images. This system of images and layers makes it very fast to build, pull, push, and copy images and it also saves on disk space.
Working with Docker Images
You can run <docker pull> to download an image from a repository. Each layer is downloaded to the host (C:\ProgramData\docker) and is stored in a separate directory. When creating your own images using Docker files, you can specify a base image using FROM. For example, the following Docker file contains two commands and it is used to create an image called my-base-image:1.0. The first command specifies a base image and the second adds some files.
FROM ubuntu:16.10
COPY . /app
If you create another image based on the first, it will reference the layers from the first image and add new layers for each new instruction as required.
FROM acme/my-base-image:1.0
CMD /app/hello.sh
Copy-on-Write
Docker uses a copy-on-write (CoW) system that only creates a new copy of a file in the current layer if the file needs to be modified. Otherwise, the read-only version of the file is always referenced in an underlying layer. CoW is designed to minimize disk I/O and keep the size of layers as small as possible.
In an upcoming article, I’ll look at how persistent volumes work in Windows.