


Saving Money with Microsoft Azure Virtual Machines
In this article I will look at some methods you can employ to save money when you deploy virtual machines into Microsoft Azure.
The Cloud is Cheaper
One goal that an IT director is tasked with when moving to the cloud is to save money. Quite honestly, you can’t do a simple calculation to determine how much money you will save when moving a server or virtual machine to Azure. This is also true if you’re looking at AWS or Google for that matter. When you run the numbers, the cost of an Azure virtual machine over 12 months is more expensive than an equivalent physical server, with the cost of that server being spread over three years.
But there are a few things to consider about the real cost of that equivalent server:
- Windows licensing: Have you included the cost of Windows Server licensing? Remember that the Azure virtual machine comes with a per-processor license, so you don’t need any device or user CALs to access it. That’s pretty important for anyone switching from a down-level operating system, such as Windows Server 2003, to a more up-to-date OS running in Azure.
- Power: You don’t have to pay for the electrical costs of running anything in Azure. That’s a relief because electricity is a significant cost to the business, and computer rooms draw a lot of that power, both to power the servers, network, and storage, and to cool the computer room.
- Facilities: You will need a lot less floor space for your IT infrastructure after a migration to Azure, even if you have employed the hybrid model, where you retain some infrastructure on-premises. This saving can translate into a reduction in rent or an increase in available office space. And you’ll definitely save a lot of money if you have moved from co-located hosting to Azure.
There are many more savings that are much more difficult to calculate, such as increased flexibility and the ability for the business to respond to opportunities more easily.
These are all savings that you can achieve by moving to Azure, assuming that your workloads and regulatory requirements are suitable. With that said, I want to show you some other things you should look at once you decide to make the move to save some of that IT budget. Maybe that’ll translate into a nice bonus, or you’ll finally get those big touch monitors that you’ve been drooling over for your PC!
Virtual Machine Specification
We’ve nearly always over-specified physical servers in the past. If you are migrating a workload from a physical machine, or using Azure Migration Accelerator in the future, then you can use this project as an opportunity to size the Azure virtual machine correctly.
There has also been a laissez-faire approach to memory sizing of virtual machines on vSphere and Hyper-V. This is thanks to features, such as Dynamic Memory, that allow a virtual machine to have access to lots of memory for anticipated or feared peak demands, but the hypervisor only assigns enough RAM to meet the demands of the actual guest workload. Azure doesn’t do the same optimization as on-premises Hyper-V. If you deploy a virtual machine with 7 GB RAM, then all of that is assigned to the virtual machine and you have to pay for it, whether it is fully used or not.
The wasteful over-allocation of physical workloads or the relaxed ‘let the system manage it’ approach of vSphere and Hyper-V memory management wastes a lot of IT budget. Because of this, use your migration project as an opportunity to right-size the memory and processor of your virtual machines. Hopefully you have a monitoring solution, such as System Center Operations Manager, that has a data warehouse full of performance statistics. Run some reports to determine what the average and peak demands to use this information to determine how many virtual processors and RAM your Azure virtual machines will actually need. As a note, I prefer using standard deviation because of the effect of data aggregation on average statistics.
As you’re analyzing your reports, you should also dig up some measurements on disk utilization. Every Azure virtual machine has two disks: system drive and temporary/paging drive.
Data should be placed onto dedicated data volumes that are stored on one or more data drives. Don’t assign a 500 GB drive to a new Azure virtual machine just because that’s what you had on-premises. Instead, figure out what is required and assign that.
Don’t worry about being locked into a specification. You can always expand a data drive later, and you can resize a virtual machine with the downtime being that of a quick reboot.
Virtual Machine Type
Do you need standard or basic virtual machines? A standard virtual machine costs more than a basic virtual machine. I differentiate the two kinds of virtual machine using this simple rule: I need a standard virtual machine if I want to do anything fancy with load balancing, auto-scaling, and so on. Basic virtual machines only get 300 IOPS per data disk versus 500 IOPS per standard machine data disk, and standard machines also offer more CPU capacity.
Most of the workloads we’ve run in the past are pretty simple: maybe there’s a web server and a database. If you’re creating a one-for-one copy of that service in Azure, then you’ll get no benefit with standard virtual machines, where you should go for basic instead. If you want to create a load balanced set of virtual machines, you’ll need to deploy an availability set for that SLA or use advanced features such as auto-scaling, and then deploy standard virtual machines.
If you start out with basic virtual machines, you can reconfigure required machines to the standard type. A reboot will follow to complete the switch.
Next, we need to address whether you need an A-series, D-series, or G-series question. On more than a few occasions, I’ve encountered people sizing deployments using D-series virtual machines for small-to-medium customers’ workloads. When I questioned this usage of a local SSD for temporary and paging storage, they said that the machine needed more performance. When I asked how they knew this, they mentioned things about the moon rising in the east, holding wet fingers in the wind, and reading tea leaves in the morning, where there was no hard empirical evidence from a performance monitor. Don’t assume that you need a D-series or G-series virtual machine. Instead, know what the workload really requires and choose a series accordingly.
Cloud Scaling
In the days of physical servers, if you needed more horsepower for a service, you probably added more RAM or maybe some CPU, which is what we call this scaling up. Virtualization made it easier to add more machines instead of adding RAM/CPU to existing machines but we rarely scaled out unless working with huge services.
Public clouds, such as AWS and Azure, were designed differently. They’re designed to scale out. When the likes of Microsoft designs the fabric and compute of Azure, they design it to survive compartmentalized failures. For example, if a rack fails, then the cloud keeps working. This drives a few things that are unusual for us legacy administrators and engineers.
We should design services in Azure with more, smaller virtual machines instead of fewer bigger machines. That might sound unusual. Surely we’re going to increase costs by deploying more machines? Yes that’s probably true on the face of it, but there are positives aspects to this approach.
The first of these is that we can the virtual machines into Availability Sets. We get an element of high availability from anti-affinity placement of the virtual machines in different domains of failure within Azure. If a host or rack fails in Azure, one of our virtual machines might go down, but the rest of the load balancing set or guest cluster will remain operational outside that domain of failure.
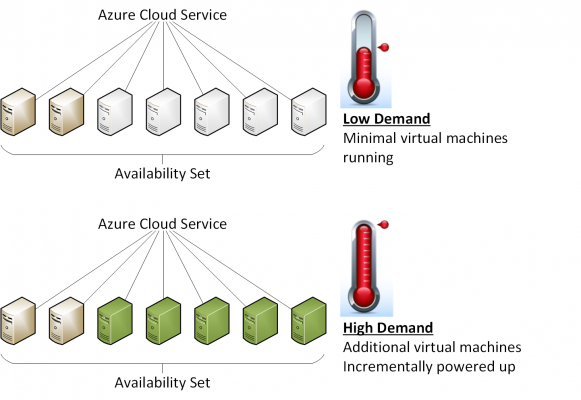
Another benefit is that we can start to avail of auto-scaling, assuming that we have a load balanced Availability Set of virtual machines. This feature is very cool because we have a pool of identical machines. We can configure Azure to keep a minimum number of these machines operational and power up more when there is demand. If demand cedes, then unneeded machines are powered down. Why is this feature useful for saving money? We’ll have enough RAM/CPU with high availability to service users even at peak demand, but we only power up what is required. In case you don’t know, you don’t pay for a non-running virtual machine (only the minor cost of storage while it has stored disks). You pay for the machines and storage while they run, you only pay for storage while they are stopped, and you get high availability.
Scheduled Power Down
If we only pay for virtual machines while they are running, then why are they running while no one is using the service? I’ve asked that question a lot during presentations, and a number of my customers have clients that only operate during normal business hours. Most of their servers aren’t used in any way between 8PM and 8AM on weekdays or at all on weekends. So why are these machines running and consuming Azure credit?
Let’s consider a typical February that has 28 days or 672 hours. If a standard A2 virtual machine costs $0.18 to run per hour, then that machine will cost me $120.96 to operate, plus storage and egress network charges. If however, I shut that machine down between 8 p.m and 8 a.m. Monday to Friday, and all day on Saturday and Sunday, with a two-hour maintenance period once per month, then my machine will run for 434 hours, instead of 672, and cost me $78.12, which will save me $42.84 per month.
Old ways of thinking should be dispensed with as we move to a new way of computing. Being inventive, learning some PowerShell and then taking advantage of Azure Automation will allow you to make this kind of saving.